Regressão não linear

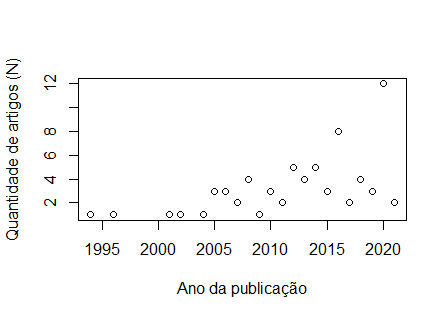
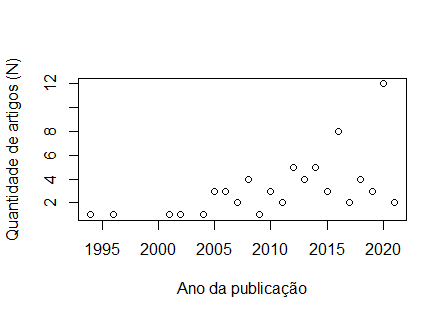
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?)) Agradeço desde já pela colaboração
{kind=link}

Chiara, Você menciona « … esse tipo de distribuição … ». Qual tipo você acha que é? Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.). Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o *processo* que gera esses dados. As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão). Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada. A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc. O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise? OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário? HTH -- Cesar Rabak [1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc. On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
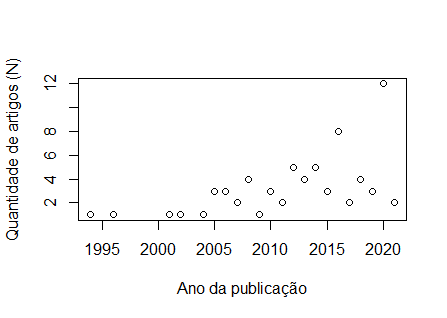
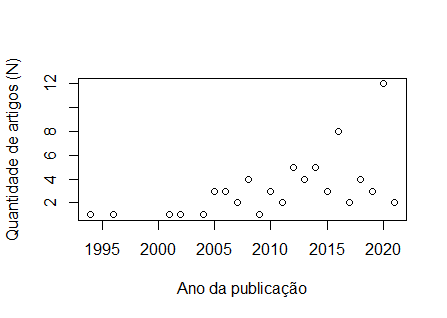
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?))
Agradeço desde já pela colaboração
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Oi, César, tudo bem? Obrigada pelo retorno. Minha pergunta é se com o passar dos anos aumentou o número de publicações sobre determinado assunto. Ao meu ver, usaria uma regressão linear simples. Mas a tentativa de usar o ajuste não linear, foi mais devido à leitura da metodologia de alguns artigos que trabalhavam com esse mesmo tipo de informação. No qual alguns utilizaram o ajuste não linear era mais adequado, no entanto, não entendi muito bem o porquê, já que não havia explicações sobre tal escolha... Acho que por isso ficou evidente minhas dúvidas. Em qua., 14 de abr. de 2021 às 13:48, Cesar Rabak <cesar.rabak@gmail.com> escreveu:
Chiara,
Você menciona « … esse tipo de distribuição … ».
Qual tipo você acha que é?
Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.).
Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o *processo* que gera esses dados.
As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão).
Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada.
A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc.
O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise?
OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário?
HTH -- Cesar Rabak
[1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc.
On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
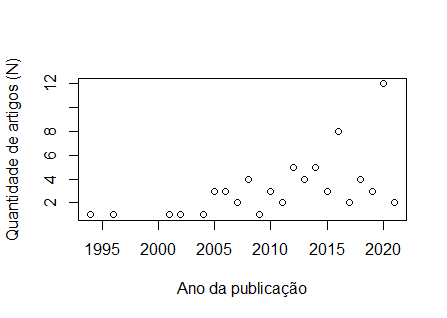
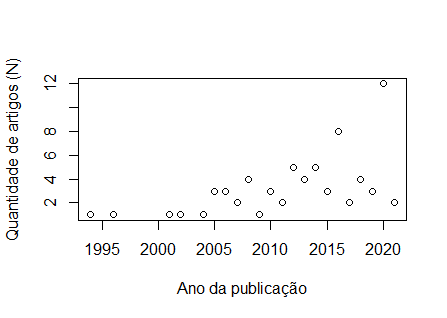
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?))
Agradeço desde já pela colaboração
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Entendida a questão no, assim denominado, domínio do problema. Aí você precisa encontrar nas referências sobre esse assunto qual seria o ciclo de vida para as publicações sobre um assunto qualquer. Visto doutra maneira, poder-se-ia fazer a pergunta desta forma: para um período suficientemente curto uma hipótese de número de publicações por ano linearmente dependente do ano (calendário) faz sentido? Como as publicações são "perenes" isto é, salvo casos excruciantes que são retratadas, elas permanecem para consulta até perderem valor intrínseco no assunto e passam a ter valor histórico, sua hipótese que ano após ano o número de publicações tem uma relação linear com o tempo indicaria uma dinâmica específica sobre esse assunto. Uma outra hipótese, só para não ficar no abstrato, mas usando um exemplo artificial, imagine que para cada certo número de publicações existentes se pudesse postular que uma nova seria gerada, algo como o famoso Jogo da Vida de Conway ou o crescimento populacional dado pela sequência de Fibonacci. Aí a modelagem matemática levaria a outro tipo de regressão. Espero que este texto ajude mais que aumente o grau de confusão 🤓! HTH -- Cesar Rabak On Thu, Apr 15, 2021 at 1:23 PM Chiara Lubich <lubichchiara@gmail.com> wrote:
Oi, César, tudo bem?
Obrigada pelo retorno.
Minha pergunta é se com o passar dos anos aumentou o número de publicações sobre determinado assunto. Ao meu ver, usaria uma regressão linear simples. Mas a tentativa de usar o ajuste não linear, foi mais devido à leitura da metodologia de alguns artigos que trabalhavam com esse mesmo tipo de informação. No qual alguns utilizaram o ajuste não linear era mais adequado, no entanto, não entendi muito bem o porquê, já que não havia explicações sobre tal escolha... Acho que por isso ficou evidente minhas dúvidas.
Em qua., 14 de abr. de 2021 às 13:48, Cesar Rabak <cesar.rabak@gmail.com> escreveu:
Chiara,
Você menciona « … esse tipo de distribuição … ».
Qual tipo você acha que é?
Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.).
Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o *processo* que gera esses dados.
As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão).
Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada.
A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc.
O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise?
OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário?
HTH -- Cesar Rabak
[1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc.
On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
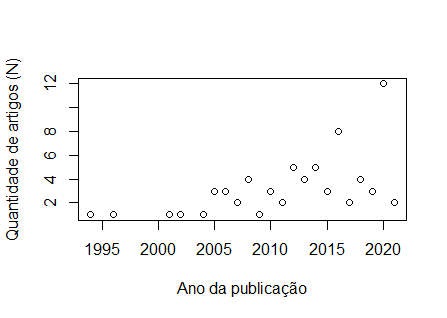
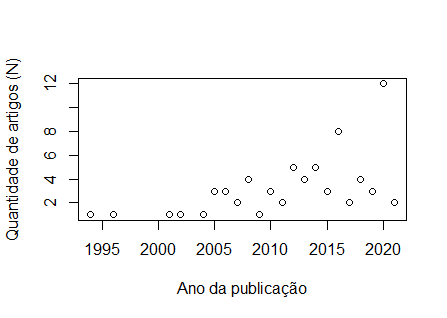
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?))
Agradeço desde já pela colaboração
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}

Prezados. Estou fazendo algumas analises mas estou insegura. Coletei moluscos por 12 meses em 6 profundidades diferentes. Rodei uma PERMANOVA e a interação entre meses e profundidade foi significativa. Agora gostaria de verificar as diferenças entre profundidades dentro de cada mês. Quando rodo a pairwise da PERMANOVA aparece a seguinte mensagem: Set of permutations < 'minperm'. Generating entire set.'nperm' >= set of all permutations: complete enumeration. Li algumas coisas que talvez eu deveria definir um design de permutação. Alguém poderia me ajudar? Atenciosamente __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC ________________________________ De: R-br <r-br-bounces@listas.c3sl.ufpr.br> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br> Enviado: quarta-feira, 14 de abril de 2021 14:48 Para: a lista Brasileira oficial de discussão do programa R. <r-br@listas.c3sl.ufpr.br> Cc: Cesar Rabak <cesar.rabak@gmail.com>; Chiara Lubich <lubichchiara@gmail.com> Assunto: Re: [R-br] Regressão não linear Chiara, Você menciona « … esse tipo de distribuição … ». Qual tipo você acha que é? Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.). Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o processo que gera esses dados. As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão). Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada. A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc. O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise? OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário? HTH -- Cesar Rabak [1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc. On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) <r-br@listas.c3sl.ufpr.br<mailto:r-br@listas.c3sl.ufpr.br>> wrote: Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?)) Agradeço desde já pela colaboração _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br<mailto:R-br@listas.c3sl.ufpr.br> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Carolina, Sem saber mais detalhes sobre os dados é difícil escapar do campo dos "palpites", mas a mensagem parece indicar que o número de casos para as permutações não tem nenhum grau de liberdade, você por acaso tem apenas 72 caso no total? On Thu, Apr 15, 2021 at 1:43 PM Carolina Lopes por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Prezados.
Estou fazendo algumas analises mas estou insegura. Coletei moluscos por 12 meses em 6 profundidades diferentes. Rodei uma PERMANOVA e a interação entre meses e profundidade foi significativa. Agora gostaria de verificar as diferenças entre profundidades dentro de cada mês. Quando rodo a pairwise da PERMANOVA aparece a seguinte mensagem: Set of permutations < 'minperm'. Generating entire set.'nperm' >= set of all permutations: complete enumeration.
Li algumas coisas que talvez eu deveria definir um design de permutação.
Alguém poderia me ajudar?
Atenciosamente __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC ------------------------------ *De:* R-br <r-br-bounces@listas.c3sl.ufpr.br> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br> *Enviado:* quarta-feira, 14 de abril de 2021 14:48 *Para:* a lista Brasileira oficial de discussão do programa R. < r-br@listas.c3sl.ufpr.br> *Cc:* Cesar Rabak <cesar.rabak@gmail.com>; Chiara Lubich < lubichchiara@gmail.com> *Assunto:* Re: [R-br] Regressão não linear
Chiara,
Você menciona « … esse tipo de distribuição … ».
Qual tipo você acha que é?
Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.).
Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o *processo* que gera esses dados.
As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão).
Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada.
A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc.
O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise?
OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário?
HTH -- Cesar Rabak
[1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc.
On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?))
Agradeço desde já pela colaboração
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Prezado Cesar. Tenho 216 amostras nas quais eu contabilizei o número total de moluscos. São 6 profundidades, 12 meses e foi em triplicata. Para cada profundidade eu tenho 3 amostras por mês. Para cada mês, 18 amostras. Eu gostaria de verificar se existe diferença entre as profundidades em cada mês. Espero que eu tenha conseguido explicar melhor o delineamento. Agradeço a atenção. __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC ________________________________ De: R-br <r-br-bounces@listas.c3sl.ufpr.br> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br> Enviado: quinta-feira, 15 de abril de 2021 21:19 Para: a lista Brasileira oficial de discussão do programa R. <r-br@listas.c3sl.ufpr.br> Cc: Cesar Rabak <cesar.rabak@gmail.com> Assunto: Re: [R-br] Teste de Pairwise para PERMANOVA Carolina, Sem saber mais detalhes sobre os dados é difícil escapar do campo dos "palpites", mas a mensagem parece indicar que o número de casos para as permutações não tem nenhum grau de liberdade, você por acaso tem apenas 72 caso no total? On Thu, Apr 15, 2021 at 1:43 PM Carolina Lopes por (R-br) <r-br@listas.c3sl.ufpr.br<mailto:r-br@listas.c3sl.ufpr.br>> wrote: Prezados. Estou fazendo algumas analises mas estou insegura. Coletei moluscos por 12 meses em 6 profundidades diferentes. Rodei uma PERMANOVA e a interação entre meses e profundidade foi significativa. Agora gostaria de verificar as diferenças entre profundidades dentro de cada mês. Quando rodo a pairwise da PERMANOVA aparece a seguinte mensagem: Set of permutations < 'minperm'. Generating entire set.'nperm' >= set of all permutations: complete enumeration. Li algumas coisas que talvez eu deveria definir um design de permutação. Alguém poderia me ajudar? Atenciosamente __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC ________________________________ De: R-br <r-br-bounces@listas.c3sl.ufpr.br<mailto:r-br-bounces@listas.c3sl.ufpr.br>> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br<mailto:r-br@listas.c3sl.ufpr.br>> Enviado: quarta-feira, 14 de abril de 2021 14:48 Para: a lista Brasileira oficial de discussão do programa R. <r-br@listas.c3sl.ufpr.br<mailto:r-br@listas.c3sl.ufpr.br>> Cc: Cesar Rabak <cesar.rabak@gmail.com<mailto:cesar.rabak@gmail.com>>; Chiara Lubich <lubichchiara@gmail.com<mailto:lubichchiara@gmail.com>> Assunto: Re: [R-br] Regressão não linear Chiara, Você menciona « … esse tipo de distribuição … ». Qual tipo você acha que é? Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.). Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o processo que gera esses dados. As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão). Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada. A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc. O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise? OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário? HTH -- Cesar Rabak [1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc. On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) <r-br@listas.c3sl.ufpr.br<mailto:r-br@listas.c3sl.ufpr.br>> wrote: Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?)) Agradeço desde já pela colaboração _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br<mailto:R-br@listas.c3sl.ufpr.br> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível. _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br<mailto:R-br@listas.c3sl.ufpr.br> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Delineamento explicado, Carolina! Resta saber se a chamada à função no R indica isso ou se ele considerou cada uma das três amostras por mês como um "fator" ou coisa que o valha e por isso não enxerga a multiplicidade para o mês × profundidade. Sem mais detalhes, por óbvio, é difícil ser assertivo, *mas* considerando o objetivo do pacote que usa médias baseadas em componentes principais, que é uma técnica usada quando se tem muitas variáveis (e especialmente correlacionadas entre si) e os seus dados, me pergunto se uma ANOVA mais convencional não seria suficiente para ajudá-la a responder a questão da pesquisa. HTH -- Cesar Rabak On Sat, Apr 17, 2021 at 6:52 PM Carolina Lopes por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Prezado Cesar. Tenho 216 amostras nas quais eu contabilizei o número total de moluscos. São 6 profundidades, 12 meses e foi em triplicata. Para cada profundidade eu tenho 3 amostras por mês. Para cada mês, 18 amostras. Eu gostaria de verificar se existe diferença entre as profundidades em cada mês.
Espero que eu tenha conseguido explicar melhor o delineamento.
Agradeço a atenção. __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC
------------------------------ *De:* R-br <r-br-bounces@listas.c3sl.ufpr.br> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br> *Enviado:* quinta-feira, 15 de abril de 2021 21:19 *Para:* a lista Brasileira oficial de discussão do programa R. < r-br@listas.c3sl.ufpr.br> *Cc:* Cesar Rabak <cesar.rabak@gmail.com> *Assunto:* Re: [R-br] Teste de Pairwise para PERMANOVA
Carolina,
Sem saber mais detalhes sobre os dados é difícil escapar do campo dos "palpites", mas a mensagem parece indicar que o número de casos para as permutações não tem nenhum grau de liberdade, você por acaso tem apenas 72 caso no total?
On Thu, Apr 15, 2021 at 1:43 PM Carolina Lopes por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Prezados.
Estou fazendo algumas analises mas estou insegura. Coletei moluscos por 12 meses em 6 profundidades diferentes. Rodei uma PERMANOVA e a interação entre meses e profundidade foi significativa. Agora gostaria de verificar as diferenças entre profundidades dentro de cada mês. Quando rodo a pairwise da PERMANOVA aparece a seguinte mensagem: Set of permutations < 'minperm'. Generating entire set.'nperm' >= set of all permutations: complete enumeration.
Li algumas coisas que talvez eu deveria definir um design de permutação.
Alguém poderia me ajudar?
Atenciosamente __________________________________________________________________________ Dra. Carolina A. Lopes Pesquisadora - Pós-doutorado Universidade Federal de Santa Catarina - UFSC ------------------------------ *De:* R-br <r-br-bounces@listas.c3sl.ufpr.br> em nome de Cesar Rabak por (R-br) <r-br@listas.c3sl.ufpr.br> *Enviado:* quarta-feira, 14 de abril de 2021 14:48 *Para:* a lista Brasileira oficial de discussão do programa R. < r-br@listas.c3sl.ufpr.br> *Cc:* Cesar Rabak <cesar.rabak@gmail.com>; Chiara Lubich < lubichchiara@gmail.com> *Assunto:* Re: [R-br] Regressão não linear
Chiara,
Você menciona « … esse tipo de distribuição … ».
Qual tipo você acha que é?
Pelos nomes que deste aos eixos, parece que a variável dependente é inteira¹ ("Qtde. de artigos [N]"), por outro lado, a variável independente é um ano calendário, que por definição é uma variável ordinal arbitrária (a faixa 1994 -- 2021 poderia ser noutros calendários diferente, por exemplo no Bahá'i de 157 a 178, etc.).
Para decidir por uma regressão (de qualquer tipo) antes de mais nada deve-se refletir sobre o fenômeno e a modelagem que o *processo* que gera esses dados.
As regressões são abordagens que nos permitem fazer ajustes dos dados experimentais à essas hipóteses modeladas e enfrenta os dois problemas dos dados obtidos por meio de observação: a) amostragem; b) perturbações que geram erros nas observações, modeladas como "ruído" ou "erros" com distribuição gaussiana de média zero e variância em função da dispersão dos dados vis-à-vis à abstração matemática (equação da regressão).
Daí a sua confusão sobre « … como são feitas as escolhas para valores de a=?, b=? e c=? » ser esperada.
A equação da regressão ("não linear") propõe uma complexa equação exponencia multiplicada pela variável independente, etc.
O quê você precisa responder é: essa curva descreve um processo que explica a geração dos dados que está em análise?
OBS.: Faz sentido incluir um ano que ainda não acabou numa regressão que conta eventos por unidade de ano calendário?
HTH -- Cesar Rabak
[1] Mais importante, parece ser o tipo de dados "de contagem" que tem outras restrições, como não poder ser menor que zero, etc.
On Wed, Apr 14, 2021 at 12:01 PM Chiara Lubich por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Bom dia, Pessoal, fiz a plotagem dos meu dados: ano n 1994 1 1996 1 2001 1 2002 1 2004 1 2005 3 2006 3 2007 2 2008 4 2009 1 2010 3 2011 2 2012 5 2013 4 2014 5 2015 3 2016 8 2017 2 2018 4 2019 3 2020 12 2021 2 [image: image.png] E vi na internet alguns vídeos em que gráficos que tinham esse tipo de distribuição, era feito o uso de Regressão Não Linear, por meio da função "nls". No entanto, tentei começar a digitar os comandos, mas não entendi como são feitas as escolhas para valores de a=?, b=? e c=?. Segue o script abaixo: plot(n ~ ano, data = chiara, xlab = "Ano da publicação", ylab = "Quantidade de artigos (N)") a_maximovalor=max(n) modelo<-nls(y~x*(1-exp(-b*x))^c, data=chiara, start = list(a= a_maximovalor, b=?, c=?))
Agradeço desde já pela colaboração
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
participantes (3)
-
 Carolina Lopes
Carolina Lopes -
 Cesar Rabak
Cesar Rabak -
 Chiara Lubich
Chiara Lubich