
Caríssimos(as) colegas(as), muito bom dia! Espero que todos se encontrem bem. Estou com uma dificuldade. Quero fazer um bubble plot usando as funções ggplot2 e dplyr, onde pretendo plotar no eixo x o gene_ID (são 84 linhas), no y a % de ocorrência da expressão na célula e no color, o valor da expressão. O meu primeiro problema é que no y são 9 tipos celulares diferentes e cada um tem, na tabela de entrada de dados, uma coluna com os dados de expressão e outra com os dados de % de ocorrência (amostra abaixo). Como eu escrevo a função geom_point para plotar o gráfico? Amostra da tabela de entrada gene BE-exp BE% CE_exp CE% E_exp E% F_exp F% HE_exp HE% L-exp L% LE-exp LE% N-exp N% SM-exp SM% ACTB 4.006 99.8 3.690 99.6 2.691 95.2 2.377 80.1 2.901 97.7 3.182 94.1 2.864 94.0 3.243 96.0 3.214 93.5 ACTG1 3.850 5.9 3.592 7.1 2.469 1.5 2.252 1.1 3.129 6.4 2.451 0.6 2.979 1.1 3.104 0 2.500 2.4 AJUBA 1.185 5.9 0.972 7.1 1.042 1.5 0.912 1.1 1.043 6.4 0.865 0.6 1.024 1.1 0 0 1.149 2.4 Muitíssimo obrigada pela ajuda! Michele -- ------------------------------------------------------------------------ *Dra. Michele Claire Breton* Técnica Superior em Bioinformática CICS - Centro de Investigação em Ciências da Saúde Faculdade de Ciências da Saúde Universidade da Beira Interior Covilhã - Castelo Branco - Portugal

Vc precisa transformar a tabela do formate wide para long. Existem varias formas. Aqui tem um exemplo https://www.datasciencemadesimple.com/reshape-in-r-from-wide-to-long-from-lo... <https://www.datasciencemadesimple.com/reshape-in-r-from-wide-to-long-from-long-to-wide/> daniel
On May 25, 2022, at 8:01 AM, Michele Claire Breton por (R-br) <r-br@listas.c3sl.ufpr.br> wrote:
Caríssimos(as) colegas(as), muito bom dia!
Espero que todos se encontrem bem.
Estou com uma dificuldade. Quero fazer um bubble plot usando as funções ggplot2 e dplyr, onde pretendo plotar no eixo x o gene_ID (são 84 linhas), no y a % de ocorrência da expressão na célula e no color, o valor da expressão. O meu primeiro problema é que no y são 9 tipos celulares diferentes e cada um tem, na tabela de entrada de dados, uma coluna com os dados de expressão e outra com os dados de % de ocorrência (amostra abaixo). Como eu escrevo a função geom_point para plotar o gráfico?
Amostra da tabela de entrada gene BE-exp BE% CE_exp CE% E_exp E% F_exp F% HE_exp HE% L-exp L% LE-exp LE% N-exp N% SM-exp SM% ACTB 4.006 99.8 3.690 99.6 2.691 95.2 2.377 80.1 2.901 97.7 3.182 94.1 2.864 94.0 3.243 96.0 3.214 93.5 ACTG1 3.850 5.9 3.592 7.1 2.469 1.5 2.252 1.1 3.129 6.4 2.451 0.6 2.979 1.1 3.104 0 2.500 2.4 AJUBA 1.185 5.9 0.972 7.1 1.042 1.5 0.912 1.1 1.043 6.4 0.865 0.6 1.024 1.1 0 0 1.149 2.4
Muitíssimo obrigada pela ajuda!
Michele
-- ------------------------------------------------------------------------ Dra. Michele Claire Breton Técnica Superior em Bioinformática CICS - Centro de Investigação em Ciências da Saúde Faculdade de Ciências da Saúde Universidade da Beira Interior Covilhã - Castelo Branco - Portugal _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.

Acho que reshape, *per se*, não é suficiente. . . É necessário efetuar aglutinações nos dados para que se tenha as nove "linhas" da tabela que gerarão as posições no eixo x do *bubble plot*, etc. Uma busca na documentação por "dplyr aggregate by group" mostrará o caminho a seguir. Se eu entendo corretamente, no final do processamento necessita-se um tibble (ou dataframe se forem usadas funções do ggplot2) com três variáveis para alimentar a função de interesse. On Wed, May 25, 2022 at 10:25 AM Daniel Guimarães Tiezzi por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Vc precisa transformar a tabela do formate wide para long.
Existem varias formas. Aqui tem um exemplo
https://www.datasciencemadesimple.com/reshape-in-r-from-wide-to-long-from-lo...
daniel
On May 25, 2022, at 8:01 AM, Michele Claire Breton por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Caríssimos(as) colegas(as), muito bom dia!
Espero que todos se encontrem bem.
Estou com uma dificuldade. Quero fazer um bubble plot usando as funções ggplot2 e dplyr, onde pretendo plotar no eixo x o gene_ID (são 84 linhas), no y a % de ocorrência da expressão na célula e no color, o valor da expressão. O meu primeiro problema é que no y são 9 tipos celulares diferentes e cada um tem, na tabela de entrada de dados, uma coluna com os dados de expressão e outra com os dados de % de ocorrência (amostra abaixo). Como eu escrevo a função geom_point para plotar o gráfico?
Amostra da tabela de entrada gene BE-exp BE% CE_exp CE% E_exp E% F_exp F% HE_exp HE% L-exp L% LE-exp LE% N-exp N% SM-exp SM% ACTB 4.006 99.8 3.690 99.6 2.691 95.2 2.377 80.1 2.901 97.7 3.182 94.1 2.864 94.0 3.243 96.0 3.214 93.5 ACTG1 3.850 5.9 3.592 7.1 2.469 1.5 2.252 1.1 3.129 6.4 2.451 0.6 2.979 1.1 3.104 0 2.500 2.4 AJUBA 1.185 5.9 0.972 7.1 1.042 1.5 0.912 1.1 1.043 6.4 0.865 0.6 1.024 1.1 0 0 1.149 2.4
Muitíssimo obrigada pela ajuda!
Michele
-- ------------------------------------------------------------------------ *Dra. Michele Claire Breton* Técnica Superior em Bioinformática CICS - Centro de Investigação em Ciências da Saúde Faculdade de Ciências da Saúde Universidade da Beira Interior Covilhã - Castelo Branco - Portugal _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.

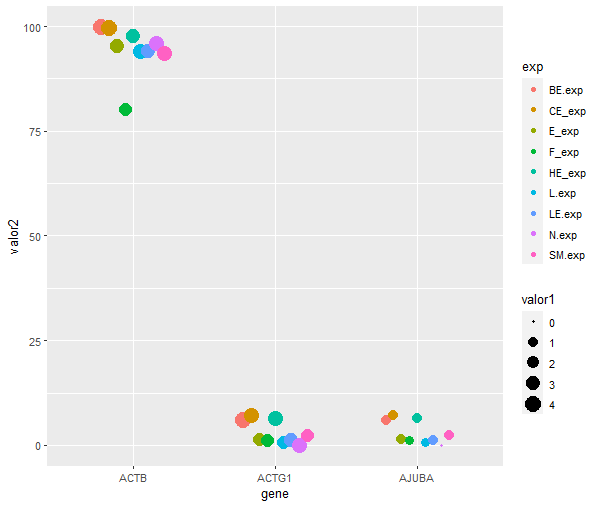
library(tidyverse) library(metan) db <- structure(list(gene = c("ACTB", "ACTG1", "AJUBA"), BE.exp = c(4.006,3.85, 1.185), BE. = c(99.8, 5.9, 5.9), CE_exp = c(3.69, 3.592, 0.972), CE. = c(99.6, 7.1, 7.1), E_exp = c(2.691, 2.469, 1.042), E. = c(95.2, 1.5, 1.5), F_exp = c(2.377, 2.252, 0.912), F. = c(80.1, 1.1, 1.1), HE_exp = c(2.901, 3.129, 1.043), HE. = c(97.7, 6.4,6.4), L.exp = c(3.182, 2.451, 0.865), L. = c(94.1, 0.6, 0.6), LE.exp = c(2.864, 2.979, 1.024), LE. = c(94, 1.1, 1.1), N.exp = c(3.243, 3.104, 0), N. = c(96L, 0L, 0L), SM.exp = c(3.214, 2.5, 1.149), SM. = c(93.5, 2.4, 2.4)), class = "data.frame", row.names = c(NA, -3L)) db1 <- db %>% select(gene,ends_with("exp")) db1 <- db1 %>% pivot_longer(cols=-1, names_to = "exp", values_to = "valor1") db2 <- db %>% select(gene,!ends_with("exp")) db2 <- db2 %>% pivot_longer(cols=-1, names_to = "per", values_to = "valor2") df <- cbind(db1,db2[-1]) df %>% ggplot(aes(gene,valor2, color=exp))+geom_point(aes(size=valor1), position = position_dodge(0.5)) seria isso? [image: image.png] *Cid Edson Mendonça Póvoas* *AnovAgro <http://www.anovagro.com/>* *Engenheiro Agrônomo - **Data Scientist* *CREA-BA: 051984991-4* *Técnico em Segurança do Trabalho * *Nº: **0012669/BA* *Tel: +55 73 99151-9565* *Lattes : *http://lattes.cnpq.br/2303498368142537 *LinkedIn :* http://br.linkedin.com/in/cidedson/ *Whatsapp :* https://wa.me/5573991519565 Em qua., 25 de mai. de 2022 às 15:14, Cesar Rabak por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
Acho que reshape, *per se*, não é suficiente. . .
É necessário efetuar aglutinações nos dados para que se tenha as nove "linhas" da tabela que gerarão as posições no eixo x do *bubble plot*, etc.
Uma busca na documentação por "dplyr aggregate by group" mostrará o caminho a seguir.
Se eu entendo corretamente, no final do processamento necessita-se um tibble (ou dataframe se forem usadas funções do ggplot2) com três variáveis para alimentar a função de interesse.
On Wed, May 25, 2022 at 10:25 AM Daniel Guimarães Tiezzi por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Vc precisa transformar a tabela do formate wide para long.
Existem varias formas. Aqui tem um exemplo
https://www.datasciencemadesimple.com/reshape-in-r-from-wide-to-long-from-lo...
daniel
On May 25, 2022, at 8:01 AM, Michele Claire Breton por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Caríssimos(as) colegas(as), muito bom dia!
Espero que todos se encontrem bem.
Estou com uma dificuldade. Quero fazer um bubble plot usando as funções ggplot2 e dplyr, onde pretendo plotar no eixo x o gene_ID (são 84 linhas), no y a % de ocorrência da expressão na célula e no color, o valor da expressão. O meu primeiro problema é que no y são 9 tipos celulares diferentes e cada um tem, na tabela de entrada de dados, uma coluna com os dados de expressão e outra com os dados de % de ocorrência (amostra abaixo). Como eu escrevo a função geom_point para plotar o gráfico?
Amostra da tabela de entrada gene BE-exp BE% CE_exp CE% E_exp E% F_exp F% HE_exp HE% L-exp L% LE-exp LE% N-exp N% SM-exp SM% ACTB 4.006 99.8 3.690 99.6 2.691 95.2 2.377 80.1 2.901 97.7 3.182 94.1 2.864 94.0 3.243 96.0 3.214 93.5 ACTG1 3.850 5.9 3.592 7.1 2.469 1.5 2.252 1.1 3.129 6.4 2.451 0.6 2.979 1.1 3.104 0 2.500 2.4 AJUBA 1.185 5.9 0.972 7.1 1.042 1.5 0.912 1.1 1.043 6.4 0.865 0.6 1.024 1.1 0 0 1.149 2.4
Muitíssimo obrigada pela ajuda!
Michele
-- ------------------------------------------------------------------------ *Dra. Michele Claire Breton* Técnica Superior em Bioinformática CICS - Centro de Investigação em Ciências da Saúde Faculdade de Ciências da Saúde Universidade da Beira Interior Covilhã - Castelo Branco - Portugal _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Veja se seria algo assim library(reshape2) library(ggplot2) library(dplyr) t <- read.delim('teste.txt') t1 <- t[,c(1,seq(2,ncol(t),2))] t2 <- t[,c(1,seq(3,ncol(t),2))] t1l <- melt(t1, idvar = 'gene') colnames(t1l)[3] <- 'exprs' t2l <- melt(t2, idvar = 'gene') colnames(t2l)[3] <- 'percentage' tl <- left_join(t1l, t2l, by='gene') ggplot(data = tl, aes(x=gene, y=exprs)) + geom_point(aes(color=percentage)) + scale_color_gradient2(midpoint=mean(tl$percentage), low="blue", mid="white", high="red", space ="Lab" ) + theme_classic() daniel
On May 25, 2022, at 8:01 AM, Michele Claire Breton por (R-br) <r-br@listas.c3sl.ufpr.br> wrote:
gene BE-exp BE% CE_exp CE% E_exp E% F_exp F% HE_exp HE% L-exp L% LE-exp LE% N-exp N% SM-exp SM% ACTB 4.006 99.8 3.690 99.6 2.691 95.2 2.377 80.1 2.901 97.7 3.182 94.1 2.864 94.0 3.243 96.0 3.214 93.5 ACTG1 3.850 5.9 3.592 7.1 2.469 1.5 2.252 1.1 3.129 6.4 2.451 0.6 2.979 1.1 3.104 0 2.500 2.4 AJUBA 1.185 5.9 0.972 7.1 1.042 1.5 0.912 1.1 1.043 6.4 0.865 0.6 1.024 1.1 0 0 1.149 2.4
participantes (4)
-
 Cesar Rabak
Cesar Rabak -
 Cid Póvoas
Cid Póvoas -
 Daniel Guimarães Tiezzi
Daniel Guimarães Tiezzi -
 Michele Claire Breton
Michele Claire Breton