Comportamento da Log-Verossimilhança - Dist. q-Exponencial

Caros amigos, Estou trabalhando com a função de log-verossimilhança da dist. q-Exponencial. A partir dela desejo obter as estimativa dos parâmetros da distribuição. Utlizo o pacote optim do R juntamente com a função Nelder-Mead. Obtenho estimativas de uma amostra controlada, ou seja uma amostra que gero através do gerador de números aleatórios dessa distribuição e que portanto conheço os parâmetros que originaram a amostra. Para alguns valores dos Parâmetros a estimativa é bem próxima dos valores dos parâmetros, entretanto quando eu ploto o gráfico da função de log verossimilhança da distribuição que estou usando os pontos que maximizam os gráficos são diferentes daes estimativas encontradas. Gostaria de saber por que isso acontece??? Se eu otimizo a função através de máxima verossimilhança era esperado que o gráfico da função de log-verossimilhança apresentasse os pontos de máximo da função bem próximos das estimativas encontradas... Alguém pode me ajudar?? será que estou construindo a função de forma errada?? Já refiz tudo e creio que a função está escrita corretamente... O que pode está acontecendo... Abaixo escrevo o código em que que utilizo para gerar uma amostra aleatória, depois estimo os parâmetros dessa amostra gerada via Nelder-Mead (pacote optim) e por fim contruo o gráfico da verossimilhança... Note que os pontos que maximizam o gráfico diferem das estimativas de máxima verossimilhaça: ### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=1.5 eta=5 n=1000 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] q_chap eta_chap ### Construindo os gráficos de log-verossimilhança eta <-seq(1, 10, l = 25) q <- seq(1.1, 1.9, l = 25) f <- function(eta,q) { ((sum(log(1 - ((1 - q)*y*(1/eta)))))/(1 - q)) + (n*log(2 - q)) + (n*log(1/eta)) } z <- outer(eta, q, f) persp(eta, q, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue") Repito o mesmo código digitado acima, apenas com a alteração de que a amostra gerada agora é para um parâmetro q menor que 1, observe que a coisa fica ainda pior nesse caso, uma vez que, sempre o menor valor de q e o menor valor de eta são os pontos de máximo do gráfico: ### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q menor que 1. q=0.5 eta=5 n=1000 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] q_chap eta_chap ### Construindo os gráficos de log-verossimilhança eta <-seq(1, 10, l = 25) q <- seq(0, 0.75, l = 25) f <- function(eta,q) { ((sum(log(1 - ((1 - q)*y*(1/eta))),na.rm=TRUE))/(1 - q)) + (n*log(2 - q)) + (n*log(1/eta)) } z <- outer(eta, q, f) persp(eta, q, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue") Em tempo, coloco aqui algumas equações importantes: função PDF da dist. q-Exponencial: Verossimilhança da dist. q-Exponencial: log-verossimilhança da dist. q-Exponencial: gostaria muito de entender o que está acontecendo e por que nunca bate as estimativas dos parâmetros com o máximo do gráfico! Obrigado, Romero.
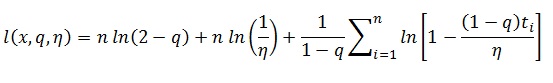{kind=link}
{kind=link}
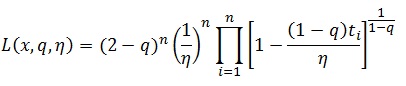{kind=link}

Romero, « Se eu otimizo a função através de máxima verossimilhança era esperado que o gráfico da função de log-verossimilhança apresentasse os pontos de máximo da função bem próximos das estimativas encontradas... » Por que você acha que essa sua expectativa estaria correta? Qual arcabouço teórico você acha que a suporta? Para começar: qual sua métrica para *bem próximo*? 2016-03-07 18:37 GMT-03:00 Romero Luiz M. Sales Filho < romero.sfilho@gmail.com>:
Caros amigos,
Estou trabalhando com a função de log-verossimilhança da dist. q-Exponencial. A partir dela desejo obter as estimativa dos parâmetros da distribuição. Utlizo o pacote optim do R juntamente com a função Nelder-Mead. Obtenho estimativas de uma amostra controlada, ou seja uma amostra que gero através do gerador de números aleatórios dessa distribuição e que portanto conheço os parâmetros que originaram a amostra. Para alguns valores dos Parâmetros a estimativa é bem próxima dos valores dos parâmetros, entretanto quando eu ploto o gráfico da função de log verossimilhança da distribuição que estou usando os pontos que maximizam os gráficos são diferentes daes estimativas encontradas. Gostaria de saber por que isso acontece??? Se eu otimizo a função através de máxima verossimilhança era esperado que o gráfico da função de log-verossimilhança apresentasse os pontos de máximo da função bem próximos das estimativas encontradas... Alguém pode me ajudar?? será que estou construindo a função de forma errada?? Já refiz tudo e creio que a função está escrita corretamente... O que pode está acontecendo...
Abaixo escrevo o código em que que utilizo para gerar uma amostra aleatória, depois estimo os parâmetros dessa amostra gerada via Nelder-Mead (pacote optim) e por fim contruo o gráfico da verossimilhança... Note que os pontos que maximizam o gráfico diferem das estimativas de máxima verossimilhaça:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=1.5 eta=5 n=1000 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q))
### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] q_chap eta_chap
### Construindo os gráficos de log-verossimilhança eta <-seq(1, 10, l = 25) q <- seq(1.1, 1.9, l = 25) f <- function(eta,q) { ((sum(log(1 - ((1 - q)*y*(1/eta)))))/(1 - q)) + (n*log(2 - q)) + (n*log(1/eta)) } z <- outer(eta, q, f) persp(eta, q, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")
Repito o mesmo código digitado acima, apenas com a alteração de que a amostra gerada agora é para um parâmetro q menor que 1, observe que a coisa fica ainda pior nesse caso, uma vez que, sempre o menor valor de q e o menor valor de eta são os pontos de máximo do gráfico:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q menor que 1. q=0.5 eta=5 n=1000 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q))
### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] q_chap eta_chap
### Construindo os gráficos de log-verossimilhança eta <-seq(1, 10, l = 25) q <- seq(0, 0.75, l = 25) f <- function(eta,q) { ((sum(log(1 - ((1 - q)*y*(1/eta))),na.rm=TRUE))/(1 - q)) + (n*log(2 - q)) + (n*log(1/eta)) } z <- outer(eta, q, f) persp(eta, q, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")
Em tempo, coloco aqui algumas equações importantes:
função PDF da dist. q-Exponencial:
Verossimilhança da dist. q-Exponencial:
log-verossimilhança da dist. q-Exponencial:
gostaria muito de entender o que está acontecendo e por que nunca bate as estimativas dos parâmetros com o máximo do gráfico!
Obrigado,
Romero.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
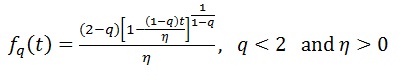{kind=link}
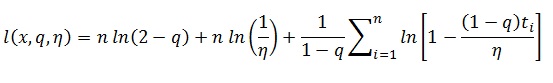{kind=link}
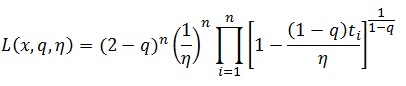{kind=link}
Oi Cesar, esse é o princípio da máxima verossimilhança... maximizando a função de log-verossimilhança (que é mais simples que a verossimilhança) o valor máximo é a estimativa do parâmetro estudado. Como estou simulando dados, ou seja, tenho uma amostra controlada, gerada computacionalmente e que sei a priori qual o valor do parâmetro que foi utilizado para gerar essa amostra, então espero que essa estimativa de máxima verossimilhança seja bastante próximas do valor do parâmetro. Na medida que o tamanho da amostra aumenta, é esperado que essa estimativa torne-se cada vez mais próxima desse valor do parâmetro devido a propriedade de consistência do estimador de máxima verossimilhança. Eu percebi que o código que eu estava utilizando estava incorreto... fiz algumas correções e os resultados melhoraram significativamente. A seguir o código correto: ### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(1.1, 1.9, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y) with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap Apesar disso, o caso em que o q é negativo ainda não me da bons resultados ... alguém sabe o que pode está acontecendo, segue o código de um exemplo com o q negativo: ### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=-1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(-2, 0, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y) with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap
Romero, O princípio não seria "Com base numa amostra causal retirada de uma população, as estimativas dos parâmetros da função de distribuição da população são aqueles valores dos parâmetros que tornam máxima a probabilidade da *amostra* observada."? (grifo meu). Como a estimativa é baseada em uma amostragem, por óbvio ela é afetada de um erro que geralmente controla-se via um IC. Por outro lado como você começa de uma "amostra controlada" ou seja você acredita que já sabe o(s) parâmetro(s) da distribuição de onde amostra, então você tem dizer qual é sua métrica para dizer se o parâmetro estimado por log-verossimilhança está "próximo" ou "afastado"? 2016-03-11 13:31 GMT-03:00 Romero Luiz M. Sales Filho < romero.sfilho@gmail.com>:
Oi Cesar,
esse é o princípio da máxima verossimilhança... maximizando a função de log-verossimilhança (que é mais simples que a verossimilhança) o valor máximo é a estimativa do parâmetro estudado. Como estou simulando dados, ou seja, tenho uma amostra controlada, gerada computacionalmente e que sei a priori qual o valor do parâmetro que foi utilizado para gerar essa amostra, então espero que essa estimativa de máxima verossimilhança seja bastante próximas do valor do parâmetro. Na medida que o tamanho da amostra aumenta, é esperado que essa estimativa torne-se cada vez mais próxima desse valor do parâmetro devido a propriedade de consistência do estimador de máxima verossimilhança.
Eu percebi que o código que eu estava utilizando estava incorreto... fiz algumas correções e os resultados melhoraram significativamente. A seguir o código correto:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(1.1, 1.9, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y)
with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap
Apesar disso, o caso em que o q é negativo ainda não me da bons resultados ... alguém sabe o que pode está acontecendo, segue o código de um exemplo com o q negativo:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=-1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(-2, 0, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y)
with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
Sim, César... De forma mais teórica o princípio é esse mesmo que vc relatou. A métrica utilizada para medir o distanciamento das estimativas para com o parâmetro é o MSE (erro quadrática médio)... Esse indicador se mostra muito alto quando o parâmetro q é menor que 0. Creio que esse comportamento se deve a restriçao observada no logaritmo da função de verossimilhança... Pelo que vejo, quando o q é menor que zero observamos alguns resultados negativos para o argumento do logaritmo, o que implica em impossibilidade de cálculo da função de log-verossimilhança ou seja durante as simulações, para situações em que tenho q negativo, tenho vários NAs como resultados da log-verossimilhança... Pensei em reparametrizar a log verossimilhança de forma a torná-la irrestrita... Mas não parece ser fácil... Alguma dica? Romero. Em 13/03/2016 22:40, "Cesar Rabak [via R-br]" < ml-node+s2285057n4665815h47@n4.nabble.com> escreveu:
Romero,
O princípio não seria "Com base numa amostra causal retirada de uma população, as estimativas dos parâmetros da função de distribuição da população são aqueles valores dos parâmetros que tornam máxima a probabilidade da *amostra* observada."? (grifo meu).
Como a estimativa é baseada em uma amostragem, por óbvio ela é afetada de um erro que geralmente controla-se via um IC.
Por outro lado como você começa de uma "amostra controlada" ou seja você acredita que já sabe o(s) parâmetro(s) da distribuição de onde amostra, então você tem dizer qual é sua métrica para dizer se o parâmetro estimado por log-verossimilhança está "próximo" ou "afastado"?
2016-03-11 13:31 GMT-03:00 Romero Luiz M. Sales Filho <[hidden email] <http:///user/SendEmail.jtp?type=node&node=4665815&i=0>>:
Oi Cesar,
esse é o princípio da máxima verossimilhança... maximizando a função de log-verossimilhança (que é mais simples que a verossimilhança) o valor máximo é a estimativa do parâmetro estudado. Como estou simulando dados, ou seja, tenho uma amostra controlada, gerada computacionalmente e que sei a priori qual o valor do parâmetro que foi utilizado para gerar essa amostra, então espero que essa estimativa de máxima verossimilhança seja bastante próximas do valor do parâmetro. Na medida que o tamanho da amostra aumenta, é esperado que essa estimativa torne-se cada vez mais próxima desse valor do parâmetro devido a propriedade de consistência do estimador de máxima verossimilhança.
Eu percebi que o código que eu estava utilizando estava incorreto... fiz algumas correções e os resultados melhoraram significativamente. A seguir o código correto:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(1.1, 1.9, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y)
with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap
Apesar disso, o caso em que o q é negativo ainda não me da bons resultados ... alguém sabe o que pode está acontecendo, segue o código de um exemplo com o q negativo:
### Gerando a amostra baseando-se nos parâmetros iniciais ### Considerando um parâmetro q positivo. q=-1.5 eta=5 n=100 u<-runif(n) y = eta*((1-(u)^((1-q)/(2-q)))/(1-q)) ### Obtendo as estimativas dos parâmetros a partir da amostra gerada anteriormente vero <- function(par,x){ q = par[1] eta = par[2] saida<-((sum(log(1 - ((1 - q)*x*(1/eta)))))/(1 - q)) + ((n)*log(2 - q)) + (n*log(1/eta)) return(-saida) } saiday<-optim(par=c(1.8,4),fn=vero, method= "Nelder-Mead",x=y ) q_chap<-saiday[1]$par[1] eta_chap<-saiday[1]$par[2] ### Construindo os gráficos de log-verossimilhança par.vals <- expand.grid(q=seq(-2, 0, l = 25), eta=seq(2, 10, l = 25)) dim(par.vals) f <- function(pars,dados) { ((sum(log(1 - ((1 - pars[1])*dados*(1/pars[2])))))/(1 - pars[1])) + (n*log(2 - pars[1])) + (n*log(1/pars[2]))} par.vals$L <- apply(par.vals, 1, f, dados = y)
with(par.vals, persp(unique(q), unique(eta), matrix(L, ncol = length(unique(eta))), xlab = expression(q), ylab = expression(eta), zlab = expression(l(q, eta)), theta= 30, phi = 30)) z<-as.matrix(par.vals) z1 <- z[order(z[,3],decreasing=T),] result<-c(z1[1,1],z1[1,2],z1[1,3]) ###Valores máximos para o gráfico da função de log-verossimilhança: result ###Estimativas de Máxima verossimilhança: q_chap eta_chap
_______________________________________________ R-br mailing list [hidden email] <http:///user/SendEmail.jtp?type=node&node=4665815&i=1> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list [hidden email] <http:///user/SendEmail.jtp?type=node&node=4665815&i=2> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forne�a c�digo m�nimo reproduz�vel.
------------------------------ If you reply to this email, your message will be added to the discussion below:
http://r-br.2285057.n4.nabble.com/R-br-Comportamento-da-Log-Verossimilhanca-... To unsubscribe from [R-br] Comportamento da Log-Verossimilhança - Dist. q-Exponencial, click here <http://r-br.2285057.n4.nabble.com/template/NamlServlet.jtp?macro=unsubscribe_by_code&node=4665802&code=cm9tZXJvLnNmaWxob0BnbWFpbC5jb218NDY2NTgwMnwtNjcxOTcyNDMw> . NAML <http://r-br.2285057.n4.nabble.com/template/NamlServlet.jtp?macro=macro_viewer&id=instant_html%21nabble%3Aemail.naml&base=nabble.naml.namespaces.BasicNamespace-nabble.view.web.template.NabbleNamespace-nabble.view.web.template.NodeNamespace&breadcrumbs=notify_subscribers%21nabble%3Aemail.naml-instant_emails%21nabble%3Aemail.naml-send_instant_email%21nabble%3Aemail.naml>

On 14/03/16 03:08, Romero Luiz M. Sales Filho wrote:
reparametrizar
Sobre isso, dá uma olhada no capítulo 2 desse livro: http://www.leg.ufpr.br/lib/exe/fetch.php/pessoais:mcie-sinape-v12.pdf No seu caso uma opção, dentre outras, é usar logit. Elias
OK, Romero! Estamos na mesma página! O uso da transformação logarítmica implica, realmente, em restringir o domínio dos parâmetros estimados. Uma forma "força bruta" seria partir para uma estimação sem a transformação log. A referência do Elias é tão mais nova, e em português que por ora, vou primeiro lê-la para ver se me resta algo a contribuir sobre outras abordagens! Grato a todos pela interessante discussão. -- Cesar Rabak 2016-03-14 5:32 GMT-03:00 Elias Teixeira Krainski < eliaskrainski@yahoo.com.br>:
On 14/03/16 03:08, Romero Luiz M. Sales Filho wrote:
reparametrizar
Sobre isso, dá uma olhada no capítulo 2 desse livro: http://www.leg.ufpr.br/lib/exe/fetch.php/pessoais:mcie-sinape-v12.pdf No seu caso uma opção, dentre outras, é usar logit.
Elias _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
Elias, muito obrigado pela dica e pela disponibilização do livro! Certamente será muito útil! César, obrigado pelo interesse no debate... Vamos em frente! Abraço, Romero. Em 15/03/2016 01:09, "Cesar Rabak [via R-br]" < ml-node+s2285057n4665821h33@n4.nabble.com> escreveu:
OK, Romero!
Estamos na mesma página!
O uso da transformação logarítmica implica, realmente, em restringir o domínio dos parâmetros estimados.
Uma forma "força bruta" seria partir para uma estimação sem a transformação log.
A referência do Elias é tão mais nova, e em português que por ora, vou primeiro lê-la para ver se me resta algo a contribuir sobre outras abordagens!
Grato a todos pela interessante discussão.
-- Cesar Rabak
2016-03-14 5:32 GMT-03:00 Elias Teixeira Krainski <[hidden email] <http:///user/SendEmail.jtp?type=node&node=4665821&i=0>>:
On 14/03/16 03:08, Romero Luiz M. Sales Filho wrote:
reparametrizar
Sobre isso, dá uma olhada no capítulo 2 desse livro: http://www.leg.ufpr.br/lib/exe/fetch.php/pessoais:mcie-sinape-v12.pdf No seu caso uma opção, dentre outras, é usar logit.
Elias _______________________________________________ R-br mailing list [hidden email] <http:///user/SendEmail.jtp?type=node&node=4665821&i=1> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
_______________________________________________ R-br mailing list [hidden email] <http:///user/SendEmail.jtp?type=node&node=4665821&i=2> https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forne�a c�digo m�nimo reproduz�vel.
------------------------------ If you reply to this email, your message will be added to the discussion below:
http://r-br.2285057.n4.nabble.com/R-br-Comportamento-da-Log-Verossimilhanca-... To unsubscribe from [R-br] Comportamento da Log-Verossimilhança - Dist. q-Exponencial, click here <http://r-br.2285057.n4.nabble.com/template/NamlServlet.jtp?macro=unsubscribe_by_code&node=4665802&code=cm9tZXJvLnNmaWxob0BnbWFpbC5jb218NDY2NTgwMnwtNjcxOTcyNDMw> . NAML <http://r-br.2285057.n4.nabble.com/template/NamlServlet.jtp?macro=macro_viewer&id=instant_html%21nabble%3Aemail.naml&base=nabble.naml.namespaces.BasicNamespace-nabble.view.web.template.NabbleNamespace-nabble.view.web.template.NodeNamespace&breadcrumbs=notify_subscribers%21nabble%3Aemail.naml-instant_emails%21nabble%3Aemail.naml-send_instant_email%21nabble%3Aemail.naml>
participantes (3)
-
 Cesar Rabak
Cesar Rabak -
 Elias Teixeira Krainski
Elias Teixeira Krainski -
 Romero Luiz M. Sales Filho
Romero Luiz M. Sales Filho