Modificação da orientação de estrutura de dados

Prezado(a)s Colegas Peço ajuda para um problema simples para o qual não encontro solução. O código abaixo gera uma estrutura de dados de trabalho: [image: demo1.png] Eu quero muda-la para esse formato: [image: demo2.png] ID <- c(1, 1, 1, 1, 2, 2, 3, 3, 3) NOME <- c("xpto", "xpto", "xpto", "xpto", "tpzo", "tpzo", "capr", "capr", "capr") IDADE <- c(1, 1, 1, 1, 57, 57, 81, 81, 81) SEXO <- c("M", "M", "M", "M", "M", "M", "F", "F", "F") CAUSA <- c("A", "B", "C", "D", "E", "F","G","H","I") df <- data.frame(ID, NOME, IDADE, SEXO, CAUSA) df Procurei soluções com as com as funções do pacote reshape2 (unmelt e dcast) e group_by do dplyr, mas não tive sucesso. Fico grato por alguma dica. Muito obrigado pela atenção. -- Paulo Eduardo de Mesquita Disciplina de Infectologia - Faculdade de Medicina Universidade do Oeste Paulista Presidente Prudente - São Paulo - Brasil telefone: 5518 97718261
{kind=link}
{kind=link}

Paulo, Certamente há uma maneira mais elegante de fazer isso, mas talvez esse código te dê alguma pista: df %>% spread(CAUSA, CAUSA) %>% unite(CAUSAS, A, B, C, D, E, F, G, H, I, sep = ",", remove = T) %>% mutate(CAUSAS = str_remove_all(CAUSAS, ",NA")) %>% mutate(CAUSAS = str_remove_all(CAUSAS, "NA,")) Abs Em qui, 29 de nov de 2018 às 10:30, Paulo Eduardo de Mesquita por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
Prezado(a)s Colegas
Peço ajuda para um problema simples para o qual não encontro solução.
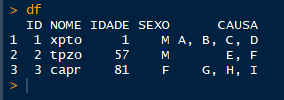
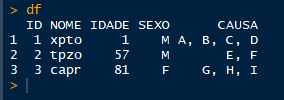
O código abaixo gera uma estrutura de dados de trabalho:
[image: demo1.png]
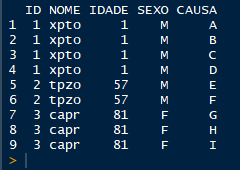
Eu quero muda-la para esse formato:
[image: demo2.png]
ID <- c(1, 1, 1, 1, 2, 2, 3, 3, 3) NOME <- c("xpto", "xpto", "xpto", "xpto", "tpzo", "tpzo", "capr", "capr", "capr") IDADE <- c(1, 1, 1, 1, 57, 57, 81, 81, 81) SEXO <- c("M", "M", "M", "M", "M", "M", "F", "F", "F") CAUSA <- c("A", "B", "C", "D", "E", "F","G","H","I")
df <- data.frame(ID, NOME, IDADE, SEXO, CAUSA)
df
Procurei soluções com as com as funções do pacote reshape2 (unmelt e dcast) e group_by do dplyr, mas não tive sucesso.
Fico grato por alguma dica.
Muito obrigado pela atenção. -- Paulo Eduardo de Mesquita Disciplina de Infectologia - Faculdade de Medicina Universidade do Oeste Paulista Presidente Prudente - São Paulo - Brasil telefone: 5518 97718261 _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
{kind=link}

Alternativa também com dplyr. library(dplyr) df %>% group_by_at(vars(-CAUSA)) %>% summarise(CAUSA = paste(CAUSA, collapse = ", ")) On Thu, Nov 29, 2018 at 12:04 PM Leonardo Mancini por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Paulo,
Certamente há uma maneira mais elegante de fazer isso, mas talvez esse código te dê alguma pista:
df %>% spread(CAUSA, CAUSA) %>% unite(CAUSAS, A, B, C, D, E, F, G, H, I, sep = ",", remove = T) %>% mutate(CAUSAS = str_remove_all(CAUSAS, ",NA")) %>% mutate(CAUSAS = str_remove_all(CAUSAS, "NA,"))
Abs
Em qui, 29 de nov de 2018 às 10:30, Paulo Eduardo de Mesquita por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
Prezado(a)s Colegas
Peço ajuda para um problema simples para o qual não encontro solução.
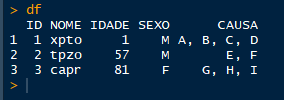
O código abaixo gera uma estrutura de dados de trabalho:
[image: demo1.png]
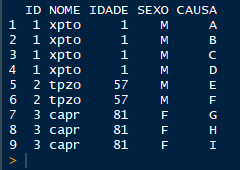
Eu quero muda-la para esse formato:
[image: demo2.png]
ID <- c(1, 1, 1, 1, 2, 2, 3, 3, 3) NOME <- c("xpto", "xpto", "xpto", "xpto", "tpzo", "tpzo", "capr", "capr", "capr") IDADE <- c(1, 1, 1, 1, 57, 57, 81, 81, 81) SEXO <- c("M", "M", "M", "M", "M", "M", "F", "F", "F") CAUSA <- c("A", "B", "C", "D", "E", "F","G","H","I")
df <- data.frame(ID, NOME, IDADE, SEXO, CAUSA)
df
Procurei soluções com as com as funções do pacote reshape2 (unmelt e dcast) e group_by do dplyr, mas não tive sucesso.
Fico grato por alguma dica.
Muito obrigado pela atenção. -- Paulo Eduardo de Mesquita Disciplina de Infectologia - Faculdade de Medicina Universidade do Oeste Paulista Presidente Prudente - São Paulo - Brasil telefone: 5518 97718261 _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- ############################################################### ## Jônatan Dupont Tatsch ## Professor do Departamento de Física ## Centro de Ciências Exatas e Naturais (CCNE) ## Universidade Federal de Santa Maria - UFSM ## Faixa de Camobi, Prédio 13 - Campus UFSM - Santa Maria, RS, Brasil - 97105-900 ## Telefone: +55(55)33012083 ## www.ufsm.br/meteorologia ###############################################################
{kind=link}
{kind=link}

Pode ser que não seja o mais rápido, mas resolve ID <- c(1, 1, 1, 1, 2, 2, 3, 3, 3) NOME <- c("xpto", "xpto", "xpto", "xpto", "tpzo", "tpzo", "capr", "capr", "capr") IDADE <- c(1, 1, 1, 1, 57, 57, 81, 81, 81) SEXO <- c("M", "M", "M", "M", "M", "M", "F", "F", "F") CAUSA <- c("A", "B", "C", "D", "E", "F","G","H","I") df <- data.frame(ID, NOME, IDADE, SEXO, CAUSA) df names <- unique(df$NOME) id_l = list() nome_l = list() idade_l = list() sexo_l = list() causa_l = list() for (i in 1:length(names)) { name = names[i] block = as.data.frame(df[df$NOME == name, ]) id = block$ID[1] nome = block$NOME[1] idade = block$IDADE[1] sexo = block$SEXO[1] causa = vector() for (j in 1:nrow(block)) { causa = paste0(causa,block$CAUSA[j], sep = ',') } print(causa) id_l[[paste0(i)]] <- id nome_l[[paste0(i)]] <- nome idade_l[[paste0(i)]] <- idade sexo_l[[paste0(i)]] <- sexo causa_l[[paste0(i)]] <- causa } unlist(causa_l) dfNew <- data.frame(ID = unlist(id_l), NOME= unlist(nome_l), IDADE= unlist(idade_l), SEXO= unlist(sexo_l), CAUSA= unlist(causa_l)) print(dfNew) Abraço daniel Daniel Tiezzi, MD, PhD Professor Associado Departamento de Ginecologia e Obstetrícia Setor de Mastologia e Oncologia Ginecológica Faculdade de Medicina de Ribeirão Preto - USP Tel.: 16 3602-2488 e-mail: dtiezzi@fmrp.usp.br
On Nov 29, 2018, at 10:30 AM, Paulo Eduardo de Mesquita por (R-br) <r-br@listas.c3sl.ufpr.br> wrote:
ID <- c(1, 1, 1, 1, 2, 2, 3, 3, 3) NOME <- c("xpto", "xpto", "xpto", "xpto", "tpzo", "tpzo", "capr", "capr", "capr") IDADE <- c(1, 1, 1, 1, 57, 57, 81, 81, 81) SEXO <- c("M", "M", "M", "M", "M", "M", "F", "F", "F") CAUSA <- c("A", "B", "C", "D", "E", "F","G","H","I")
df <- data.frame(ID, NOME, IDADE, SEXO, CAUSA)
df
participantes (4)
-
 Daniel Guimarães Tiezzi
Daniel Guimarães Tiezzi -
 Jônatan
Jônatan -
 Leonardo Mancini
Leonardo Mancini -
 Paulo Eduardo de Mesquita
Paulo Eduardo de Mesquita