Re: [R-br] Como escolher o melhor conjunto de dados imputador no MICE

Técnicas de bootstraping têm sido sugeridas para serem usadas *em conjunto* com imputação (geralmente múltipla como deseja o OP) mas não como uma solução para os valores inexistentes. HTH 2017-04-24 9:38 GMT-03:00 Edson Lira <edinhoestat@yahoo.com.br>:
Não seria o caso de bootstrap? Quick-R: Bootstrapping <http://www.statmethods.net/advstats/bootstrapping.html>
Quick-R: Bootstrapping You can bootstrap a single statistic or a vector (e.g., regression weights). This section will get you started w... <http://www.statmethods.net/advstats/bootstrapping.html>
Prof. Edson Lira, Me Estatístico Manaus-Amazonas
Em Sexta-feira, 21 de Abril de 2017 10:16, Cesar Rabak via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Elias,
A imputação é uma técnica que super simplificadamente objetiva colocar dados em variáveis cujos valores estão ausentes para não "perturbar" uma determinada estatística e permitir analisar as outras variáveis dos casos sob estudo.
Um exemplo simples seria colocar a média da variável em todos os casos de valores ausentes¹.
No seu caso que você deseja fazer uma pesquisa usando redes bayesianas haveria necessidade de ver se a abordagem em si da imputação faria sentido e então ver qual (tipo) seria mais apropriada.
Há uma extensa literatura sobre esse tema, que suponho você esteja familiarizado e consultando-a, e pelo meu contato com o tema quer me parecer que há uma certa preferência (do jeito da imputação) em função do domínio do problema.
HTH -- Cesar Rabak
[1] Bem simples, vou elidir a discussão sobre vantagens e desvantagens dessa específica abordagem e propriedade em função da quantidade de dados faltantes.
2017-04-19 0:34 GMT-03:00 Elias Carvalho via R-br < r-br@listas.c3sl.ufpr.br>:
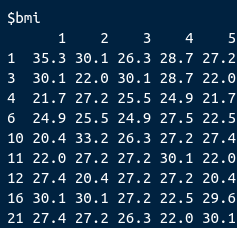
Usando o pacote mice fiz o seguinte teste (imputação de dados): imp <- mice(nhanes) Isso gerou 5 conjuntos de dados imputados: imp$imp$bmi
Eu gostaria de entender como escolher o melhor dataset imputado Por exemplo, para bmi (acima) qual das 5 colunas será a melhor escolha? Eu achei vários exemplos usando regressão logistica, mas eu não vou rodar uma regressão logistica, vou usar os dados para criar uma rede bayesiana. Alguém poderia me ajudar por favor? --
*In Jesu et Maria* *Obrigado* *Prof. Elias Carvalho*
"Felix, qui potuit rerum cognoscere causas" (Virgil 29 BC) "Blessed is he who has been able to understand the cause of things"
______________________________ _________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/ cgi-bin/mailman/listinfo/r-br <https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br> Leia o guia de postagem (http://www.leg.ufpr.br/r-br- guia <http://www.leg.ufpr.br/r-br-guia>) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forne�a c�digo m�nimo reproduz�vel.
{kind=link}
participantes (1)
-
 Cesar Rabak
Cesar Rabak