regressão polinomial: gráfico e valor máximo

Saudações a todos desta lista, Estou tentando reproduzir um exemplo de regressão polinomial do livro do Banzatto e Kronka. Minhas dúvidas são: 1. Como reproduzir exatamente o gráfico ilustrado no exemplo? O gráfico que consegui fazer está parecido porém não está igual. O gráfico apresentado no livro encontra-se neste link: https://www.dropbox.com/s/qyv7ofwryegcu7m/figura.jpg?dl=0 2. Como encontrar o valor de X que anula a derivada primeira? E depois como encontrar o máximo da função? Grato, Maurício Segue o CMR: ################################################################################ #Experimento inteiramente casualizado com 4 repetições para estudar os efeitos de #7 doses de gesso (tratamentos): #0, 50, 100, 150, 200, 250 e 300 kg/ha sobre diversas características do feijoeiro #Para a característica "peso de 1000 sementes", tem-se os resultados obtidos em gramas peso = c(134.8, 139.7, 147.6, 132.3, 161.7, 157.7, 150.3, 144.7, 160.7, 172.7, 163.4, 161.3, 169.8, 168.2, 160.7, 161.0, 165.7, 160.0, 158.2, 151.0, 171.8, 157.3, 150.4, 160.4, 154.5, 160.4, 148.8, 154.0) tratamento = factor(rep(seq(0,300,50), each=4)) dados = data.frame(peso, tratamento) attach(dados) niveis.tratamento = seq(0,300,50) contrasts(dados$tratamento) = contr.poly(niveis.tratamento) contrasts(dados$tratamento) modelo.aov = aov(peso ~ tratamento, dados) summary(modelo.aov) summary(modelo.aov, split = list(tratamento = list(L = 1, Q = 2, C=3, Dev=c(4,5,6)))) plot(c(0,300), c(130,175), type="n", xlab="Doses de gesso (kg/ha)", ylab="Peso (g) de 1000 sementes") d = rep(seq(0,300,50), each=4) med_t = rep(tapply(peso,tratamento,mean),each=4) points(d,med_t) x = seq(0,300,0.1) lines(x, (predict(lm(peso ~ I(d)+I(d^2)+I(d^3)),data.frame(d=x))),lty=2, col="blue")

Olá é só retirar o cubo: I(d^3) ficando assim: lines(x, (predict(lm(peso ~ I(d)+I(d^2)),data.frame(d=x))),lty=2, col="blue") saudações Em 20/06/2016 20:34, Maurício Lordêlo via R-br escreveu:
Saudações a todos desta lista, Estou tentando reproduzir um exemplo de regressão polinomial do livro do Banzatto e Kronka. Minhas dúvidas são: 1. Como reproduzir exatamente o gráfico ilustrado no exemplo? O gráfico que consegui fazer está parecido porém não está igual. O gráfico apresentado no livro encontra-se neste link: https://www.dropbox.com/s/qyv7ofwryegcu7m/figura.jpg?dl=0 2. Como encontrar o valor de X que anula a derivada primeira? E depois como encontrar o máximo da função? Grato, Maurício
Segue o CMR: ################################################################################ #Experimento inteiramente casualizado com 4 repetições para estudar os efeitos de #7 doses de gesso (tratamentos): #0, 50, 100, 150, 200, 250 e 300 kg/ha sobre diversas características do feijoeiro #Para a característica "peso de 1000 sementes", tem-se os resultados obtidos em gramas peso = c(134.8, 139.7, 147.6, 132.3, 161.7, 157.7, 150.3, 144.7, 160.7, 172.7, 163.4, 161.3, 169.8, 168.2, 160.7, 161.0, 165.7, 160.0, 158.2, 151.0, 171.8, 157.3, 150.4, 160.4, 154.5, 160.4, 148.8, 154.0) tratamento = factor(rep(seq(0,300,50), each=4)) dados = data.frame(peso, tratamento) attach(dados)
niveis.tratamento = seq(0,300,50) contrasts(dados$tratamento) = contr.poly(niveis.tratamento) contrasts(dados$tratamento) modelo.aov = aov(peso ~ tratamento, dados) summary(modelo.aov) summary(modelo.aov, split = list(tratamento = list(L = 1, Q = 2, C=3, Dev=c(4,5,6))))
plot(c(0,300), c(130,175), type="n", xlab="Doses de gesso (kg/ha)", ylab="Peso (g) de 1000 sementes") d = rep(seq(0,300,50), each=4) med_t = rep(tapply(peso,tratamento,mean),each=4) points(d,med_t) x = seq(0,300,0.1) lines(x, (predict(lm(peso ~ I(d)+I(d^2)+I(d^3)),data.frame(d=x))),lty=2, col="blue")
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forne�a c�digo m�nimo reproduz�vel.

O ponto de máximo você aplica o cálculo. A expressão é simples. Este conjunto de dados além de outros do Banzatto e Kronka e outras obras (Pimental, Sonia Vieira, Zimmermann, mais de 15 obras e 350 datasets) então sendo documentadas no pacote desenvolvimento pelo PET Estatística UFPR (alerta de propaganda), o labestData (*lab*oratório de *est*atística): https://github.com/pet-estatistica/labestData. Este dataset é chamado de BanzattoQd7.2.1 no pacote ( https://github.com/pet-estatistica/labestData/blob/88f404857f39a1b047231d8a1...). O meu CMR faz a leitura a partir do fonte dos dados no repositório. Se instalar o pacote, terá à disposição datasets das obras nacionais de estatística para usar em sala de aula e tutoriais. rm(list = ls()) url <- paste0("https://raw.githubusercontent.com/pet-estatistica/", "labestData/88f404857f39a1b047231d8a1aab8000fcb305b1/", "data-raw/BanzattoQd7.2.1.txt") BanzattoQd7.2.1 <- read.table(url, header = TRUE, sep = "\t") str(BanzattoQd7.2.1) # Polinômio ortogonal. m0 <- lm(peso ~ poly(gesso, degree = 2), data = BanzattoQd7.2.1) # Polinômio. m0 <- lm(peso ~ poly(gesso, degree = 2, raw = TRUE), data = BanzattoQd7.2.1) m0 <- lm(peso ~ gesso + I(gesso^2), data = BanzattoQd7.2.1) coef(m0) pred <- data.frame(gesso = seq(min(BanzattoQd7.2.1$gesso), max(BanzattoQd7.2.1$gesso), length.out = 30)) ci <- predict(m0, newdata = pred, interval = "confidence") pred <- cbind(pred, ci) ylim <- extendrange(c(BanzattoQd7.2.1$peso, ci)) # Do cálculo: f(x) = a * x^2 + b * x +c, # então f'(x) = 0 é max/min = -b/(2 * a). xmax <- -coef(m0)["gesso"]/(2 * coef(m0)["I(gesso^2)"]) plot(peso ~ gesso, data = BanzattoQd7.2.1) with(pred, matlines(x = gesso, y = cbind(fit, lwr, upr), col = c(1, 2, 2), lty = c(1, 2, 2))) abline(v = xmax, h = predict(m0, newdata = list(gesso = xmax)), lty = 2, col = 3) À disposição. Walmes.

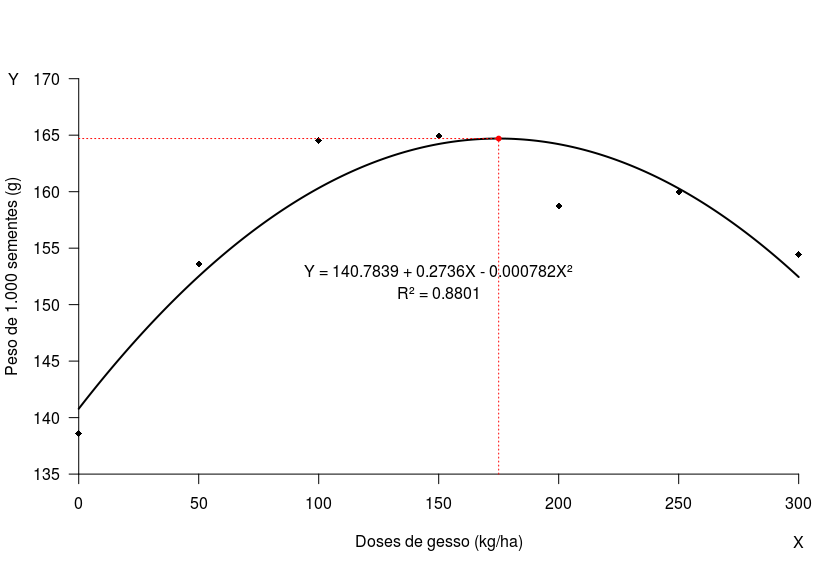
Maurício e colegas, boa tarde! Mais uma opção de código para o problema. [image: Imagem inline 1] # <code r> # DIC 4 rep x 7 doses de gesso (trat): 0, 50, 100, 150, 200, 250, 300 kg/ha # Peso de 1.000 sementes (peso, gramas) peso <- c(134.8, 139.7, 147.6, 132.3, 161.7, 157.7, 150.3, 144.7, 160.7, 172.7, 163.4, 161.3, 169.8, 168.2, 160.7, 161.0, 165.7, 160.0, 158.2, 151.0, 171.8, 157.3, 150.4, 160.4, 154.5, 160.4, 148.8, 154.0) trat <- rep(seq(0,300,50), each=4) dados <- data.frame(peso, trat=as.factor(trat)) # Método dos Polinômios Ortogonais - Banzato & Kronka, p. 204 contrasts(dados$trat) = contr.poly(levels(dados$trat)); contrasts(dados$trat) fit1 = aov(peso ~ trat, dados) summary(fit1) # anova(fit1) summary(fit1, split = list(trat = list(LIN = 1, QUA = 2, CUB=3, DESVIOS=4:6))) # Df Sum Sq Mean Sq F value Pr(>F) # trat 6 1941.8 323.6 7.668 0.000188 *** # trat: LIN 1 423.2 423.2 10.026 0.004653 ** # trat: QUA 1 1285.8 1285.8 30.465 1.78e-05 *** # trat: CUB 1 155.0 155.0 3.673 0.068997 . # trat: DESVIOS 3 77.8 25.9 0.614 0.613269 # Residuals 21 886.3 42.2 model.tables(fit1, "means") trat.m <- tapply(peso, trat, mean); trat.m # Uso do ajuste quadrático fit2 <- lm(peso ~ I(trat)+I(trat^2)) summary(fit2) coef(fit2) eq <- paste0("Y = ", round(coef(fit2)[1], 4), " + ", round(coef(fit2)[2], 4), "X - ", abs(round(coef(fit2)[3], 6)), "X²"); eq # Coeficiente de determinação summary(fit2)$r.sq cor(fitted(fit2), peso)**2 sumsq <- summary(fit1, split = list(trat = list(LIN = 1, QUA = 2, CUB=3, RES=4:6)))[[1]][2] rsq <- sum(sumsq[2:3,])/sumsq[1,]; rsq # Banzato & Kronka, p. 209 eq.r <- paste0("R² = ", round(rsq, 4)); eq.r # Predições pred <- data.frame(trat = seq(0,300,1)) pred$val <- predict(fit2, pred); head(pred) # Gráfico par(xpd=T) plot(c(0,300), c(135,170), type="n", xlab="Doses de gesso (kg/ha)", ylab="Peso de 1.000 sementes (g)", bty="n", xaxs="i", yaxs="i", las=1) points(as.numeric(names(trat.m)), trat.m, pch=18, cex=1) lines(pred$trat, pred$val, lwd=2, lty=1, col=1) text(300, 129, "X") text(-27, 170, "Y") text(150, 153, eq, adj=c(0.5,0.5)) text(150, 151, eq.r, adj=c(0.5,0.5)) # Max - Método 1 ymax <- max(pred$val); ymax # 164.7042 gramas xmax <- pred[which.max(pred$val), "trat"]; xmax # com 175 Kg/ha de gesso segments(xmax, 135, xmax, ymax, lty=3, col=2) segments(0, ymax, xmax, ymax, lty=3, col=2) points(xmax, ymax, pch=20, col=2) # Max - Método 2 # ax^2 + bx + c coefs <- data.frame(t(coef(fit2))); names(coefs) <- letters[3:1]; coefs with(coefs, -b/(2*a)) # 174.8403 with(coefs, -(b^2 - 4*a*c)/(4*a)) # 164.7043 # Max - Método 3 fun <- function(x) 140.7839 + 0.2736*x - 0.000782*x**2 fun(175) # optimize(fun, interval=c(0, 300), maximum=F) optimize(fun, interval=c(0, 300), maximum=T) # $maximum # [1] 174.9361 # # $objective # [1] 164.7152 # Max - Derivadas D1 <- D(expression(140.7839 + 0.2736*x - 0.000782*x**2), "x"); D1 # 0.2736 - 0.000782 * (2 * x) # 0.2736 - 0.001564x D2 <- D(D1, "x"); D2 # -(0.000782 * 2) # -0.001564 # 0.2736 - 0.001564x = 0 solve(0.001564, 0.2736) # Máximo # [1] 174.9361 fun(174.9361) # 164.7152 deriva <- deriv(~140.7839 + 0.2736*x - 0.000782*x**2,"x"); deriva x <- 175; eval(deriva) x <- 174.8403; eval(deriva) x <- 174.9361; eval(deriva) # </code> ================================================ Éder Comunello Researcher at Brazilian Agricultural Research Corporation (Embrapa) DSc in Agricultural Systems Engineering (USP/Esalq) MSc in Environ. Sciences (UEM), Agronomist (UEM) --- Embrapa Agropecuária Oeste, Dourados, MS, Brazil |<O>| ================================================ GEO, -22.2752, -54.8182, 408m UTC-04:00 / DST: UTC-03:00 Em 20 de junho de 2016 19:34, Maurício Lordêlo <r-br@listas.c3sl.ufpr.br> escreveu:
Saudações a todos desta lista, Estou tentando reproduzir um exemplo de regressão polinomial do livro do Banzatto e Kronka. Minhas dúvidas são: 1. Como reproduzir exatamente o gráfico ilustrado no exemplo? O gráfico que consegui fazer está parecido porém não está igual. O gráfico apresentado no livro encontra-se neste link: https://www.dropbox.com/s/qyv7ofwryegcu7m/figura.jpg?dl=0 2. Como encontrar o valor de X que anula a derivada primeira? E depois como encontrar o máximo da função? Grato, Maurício
Segue o CMR:
################################################################################ #Experimento inteiramente casualizado com 4 repetições para estudar os efeitos de #7 doses de gesso (tratamentos): #0, 50, 100, 150, 200, 250 e 300 kg/ha sobre diversas características do feijoeiro #Para a característica "peso de 1000 sementes", tem-se os resultados obtidos em gramas peso = c(134.8, 139.7, 147.6, 132.3, 161.7, 157.7, 150.3, 144.7, 160.7, 172.7, 163.4, 161.3, 169.8, 168.2, 160.7, 161.0, 165.7, 160.0, 158.2, 151.0, 171.8, 157.3, 150.4, 160.4, 154.5, 160.4, 148.8, 154.0) tratamento = factor(rep(seq(0,300,50), each=4)) dados = data.frame(peso, tratamento) attach(dados)
niveis.tratamento = seq(0,300,50) contrasts(dados$tratamento) = contr.poly(niveis.tratamento) contrasts(dados$tratamento) modelo.aov = aov(peso ~ tratamento, dados) summary(modelo.aov) summary(modelo.aov, split = list(tratamento = list(L = 1, Q = 2, C=3, Dev=c(4,5,6))))
plot(c(0,300), c(130,175), type="n", xlab="Doses de gesso (kg/ha)", ylab="Peso (g) de 1000 sementes") d = rep(seq(0,300,50), each=4) med_t = rep(tapply(peso,tratamento,mean),each=4) points(d,med_t) x = seq(0,300,0.1) lines(x, (predict(lm(peso ~ I(d)+I(d^2)+I(d^3)),data.frame(d=x))),lty=2, col="blue")
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
participantes (4)
-
 Maurício Lordêlo
Maurício Lordêlo -
 salah
salah -
 Walmes Zeviani
Walmes Zeviani -
 Éder Comunello
Éder Comunello