
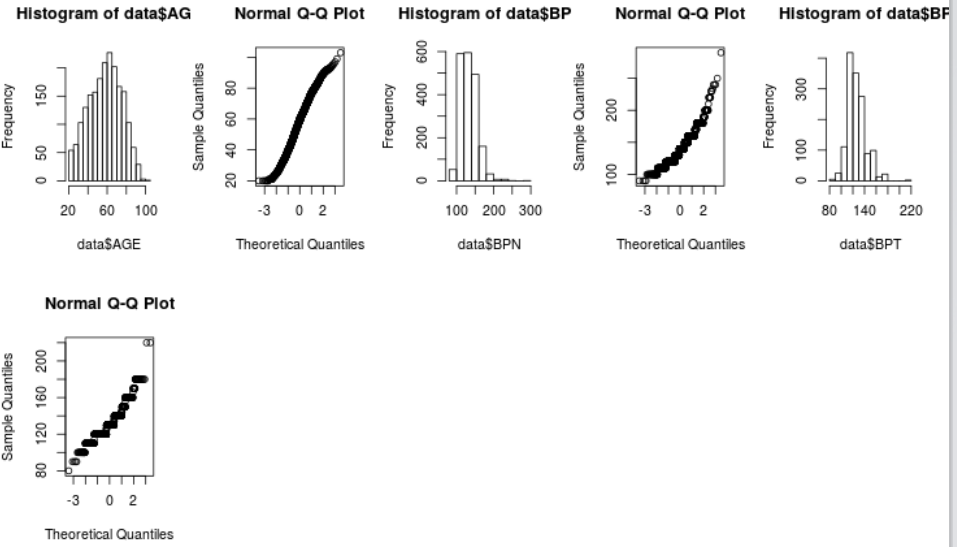
Elias, bom dia! Segue uma sugestão, caso ainda tenha interesse... ### <code r> df <- data.frame( AGE = c(21,31,44,46,49,50,52,64,23,33), AGE2 = c(21,31,44,46,49,50,52,64,23,33)+rnorm(10)*10, PHA = factor(as.character(c(1,1,1,1,1,1,1,1,2,2)), lev=1:2, lab=c("NO", "YES")), SMK = factor(as.character(c(1,1,1,1,1,1,1,1,1,1)), lev=1:2, lab=c("NO", "YES")), ALC = factor(as.character(c(1,1,1,1,1,NA,2,NA,1,NA)), lev=1:2, lab=c("NO", "YES"))) str(df) verNorm <- function(df) { require(moments) fac <- sapply(names(df), function(x) is.factor(df[,x])) sapply(names(df[!fac]), function(x) { skew <- round(skewness(df[,x]),2) kurt <- round(kurtosis(df[,x]),2) res <- data.frame(skew, kurt) x11() # uma janela para cada par de gráficos par(mfrow=c(1,2)) hist(df[,x], main=x) qqnorm(df[,x]); qqline(df[,x], col=2) layout(1) return(res)}) } verNorm(df) # AGE AGE2 # skew -0.09 -0.64 # kurt 1.99 3.15 ### </code> ================================================ Éder Comunello Agronomist (UEM), MSc in Environ. Sciences (UEM) DSc in Agricultural Systems Engineering (USP/Esalq) Brazilian Agricultural Research Corporation (Embrapa) Dourados, MS, Brazil |<O>| ================================================ GEO, -22.2752, -54.8182, 408m UTC-04:00 / DST: UTC-03:00 Em 6 de maio de 2016 08:12, Elias Carvalho <ecacarva@gmail.com> escreveu:
Bom dia Pessoal
Eu tenho o seguinte data frame:
'data.frame': 1999 obs. of 14 variables: $ AGE: int 21 31 44 46 49 50 52 64 23 33 ... $ PHA: Factor w/ 2 levels "NO","YES": 1 1 1 1 1 1 1 1 2 2 ... $ SMK: Factor w/ 2 levels "NO","YES": 1 1 1 1 1 1 1 1 1 1 ... $ ALC: Factor w/ 2 levels "NO","YES": 1 1 1 1 1 NA 2 NA 1 NA ...
E preciso rodar uma rotina para verificar a normalidade de cada variável de uma só vez, então fiz assim (ps: me perdoem o 'for' eu sou programador das antigas e ainda estou aprendendo a user os ...apply):
for (x in 1:length(names(data)))* # vai de 1 a 4 passando por todas as variáveis * { * # Insere o nome da variável em uma matriz* commandP <- paste("nmatrix[",x,",1] <- names(data)[x]", sep="") eval(parse(text=commandP)) * # aplicar apenas para variaveis continuas* * if (!is.factor(data$names(data)[x])) * { *# na coluna 2 da matriz insere valores referente a skewness* commandP <- paste("nmatrix[",x,",2] <- round(skewness(data$", names(data)[x],"),2)", sep="") eval(parse(text=commandP)) *# na coluna3 da matriz insere valores referente a kurtosis* commandP <- paste("nmatrix[",x,",3] <- round(kurtosis(data$", names(data)[x],"),2)", sep="") eval(parse(text=commandP)) * # gera um histograma para cada variável* já com par(mfrow...) calculado de acordo com o # numero de variáveis commandP <- paste("hist(data$", names(data)[x],")", sep="") eval(parse(text=commandP)) *# gera um gráfico de quartil para cada variável já com par(mfrow...) calculado de * * # acordo **com a quantidade de variáveis* commandP <- paste("qqnorm(data$", names(data)[x],")", sep="") eval(parse(text=commandP)) * # Insere a linha no gráfico * commandP <- paste("abline(0,1)", sep="") eval(parse(text=commandP)) }
O Resultado que quero parecido com o abaixo, mas para todas as variáveis:
nmatrix [,1] [,2] [,3] [1,] "AGE" "-0.13" "2.28"
O meu problema é na linha if (!is.factor(data$names(data)[x])) que identifica todas as variáveis como caracter, o que não está errado, pois pega por exemplo "AGE" e então sempre retorna falso e na verdade eu queria algo como "!is.factor(data$AGE), !is.factor(data$SMK)....
ou se alguem conhecer um pacote que faça isso de maneira mais fácil agradeço a sugestão
Obrigado -
Elias <http://lattes.cnpq.br/4248328961021251>
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}